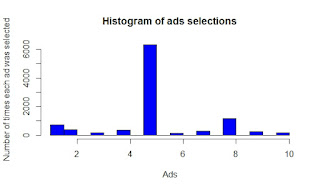
Esquisse R Package
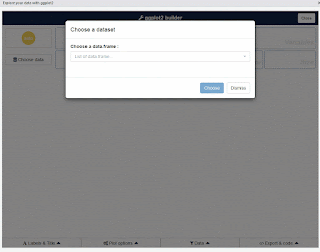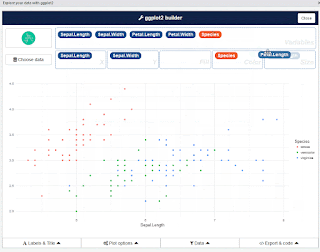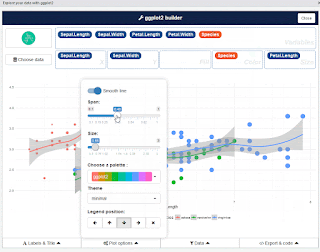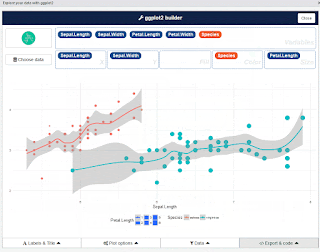
The purpose of this add-in is to let you explore your data quickly to extract the information they hold. You can only create simple plots, you won't be able to use custom scales and all the power of ggplot2. This is just the start! This addin allows you to interactively explore your data by visualizing it with the ggplot2 package. It allows you to draw bar graphs, curves, scatter plots, histograms, then export the graph or retrieve the code generating the graph. Installation Install from CRAN with : # From CRAN install.packages( " esquisse " ) Add data & drag n drop to see visual miracle.